接下來,回到本專案的正題,直接把先前爬出的第一層議題欄位,餵進去處理。
View(as.character(dfl$title))
seg<-mixseg[as.character(dfl$title)]
View(seg)
江~江~ 結果就是長這樣子
來看看前50是那些內容吧!
segA_top50<-sort(table(seg),decreasing = TRUE)[1:50]
View(segA_top50)
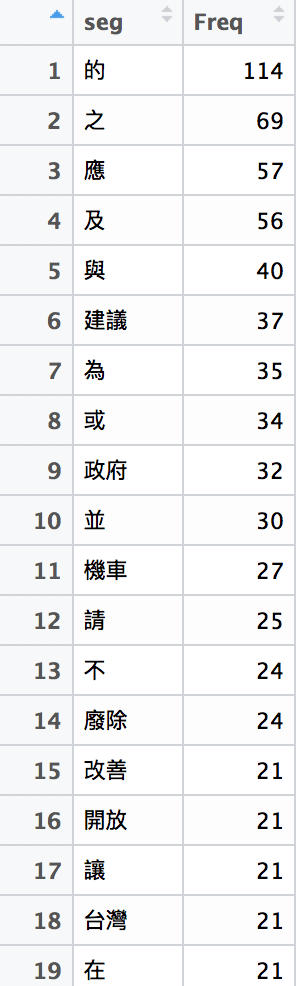
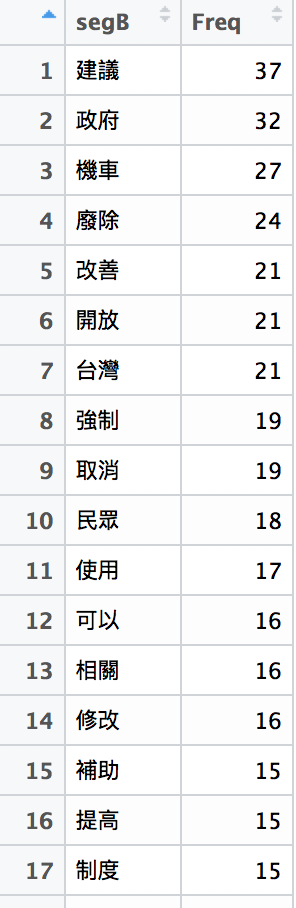
看來是一些單字無義的詞句,用掉最多! 直接濾掉字元長度>1
segB<-seg[nchar(seg)>1]#table
segB_top50<-sort(table(segB),decreasing = TRUE)[1:50]#table
segB_top50=as.data.frame(segB_top50)#table->data.frame
View(segB_top50)